
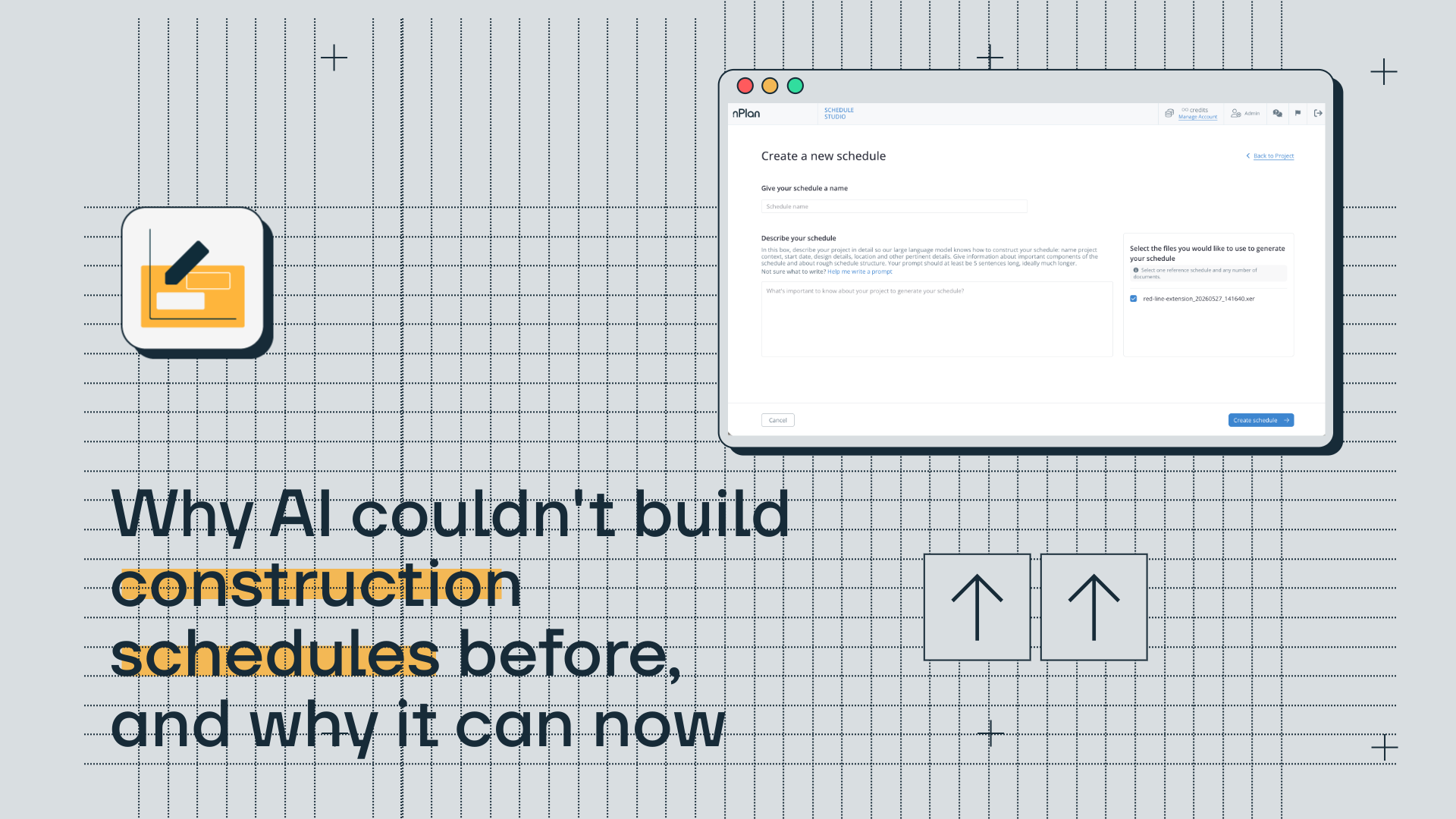
The impact of extreme events on project delay
In early 2022, nPlan conducted a study on close to 500,000 schedules and found that around 80% of projects are delayed.
In early 2022, nPlan conducted a study on close to 500,000 schedules and found that around 80% of projects are delayed.
While it is a high number, I’m sure it is not surprising to many people reading this given the headlines we see every year around large infrastructure projects running over time and over budget. What may in fact be a more surprising statistic exposed in the report is that less than 25% of activities in projects are delivered late. This means that while the majority of activities in projects are delivered well, we still see an extraordinary number of projects being delayed (and ⅓ are delayed by more than a year). This begs the question: “where are projects going wrong”? In two words, long tails.

What are “long tails”?
In the field of probability and statistics, the long tails of a distribution refers to the area of the distribution that has some meaningful probability and is far away from the mode / peak of the distribution. The diagram below illustrates a distribution with a long right tail (highlighted in red).

Long tails are present in the study of online platforms, finance, insurance and social networks, to name a few. A classic example of a long-tailed distribution is a Pareto distribution, named after Vilfredo Pareto who is also known for the “80–20” principle. While studying land ownership in Italy, he discovered that roughly 20% of the population owned 80% of all the land. It turns out this principle applies to a vast number different areas of nature, where 80% of outcomes are due to 20% of causes. Many times this is referred to as a “Power Law”, and when present is an indication that the phenomena we’re observing is not normally distributed.
Below is an image showing the distribution of completion ratios* of all activities in our data set. The vast majority of the data sits in the range of 0–1 which aligns with the statistic in the introduction. Perhaps more interesting is the occurrence of activities with really large completion ratios, greater than 10 or even 15 times the original planned duration! Note that this graph had to be cut off for the sake of presentability but we see instances in our dataset of activities that are even 100 times delayed. This is the long-tail of activity durations, and what I believe contributes to the delays we see in construction today.

The plot above demonstrates the existence of long-tail events in our historical project data, yet to this day the status quo in schedule risk management is to disregard tail events entirely. I want to use the rest of this post to examine what happens when we disregard tail events in schedule risk management and explain the dangers of these kinds of approaches.
*A completion ratio is the ratio of actual duration to planned duration. In other words, it’s a measure of how long an activity took as a multiple of its planned duration.
The Status Quo — Quantitative Schedule Risk Analysis (QSRA)
QSRA is the most common practice when it comes to creating a forecast of project outcomes and also for evaluating what are the top risks in the project based on an accurate schedule. It starts with the assumption that each activity carries with it a certain level of uncertainty and a level of susceptibility to discrete risks, and so by modeling that uncertainty we can create probabilistic forecasts of projects that help project managers in making better decisions about how to allocate resources. Typically, the way activity duration uncertainties are modeled is using one of the following 3 distributions:

These 3 distributions are very intuitive because they are defined by setting 2 or 3 parameters — the best case outcome (minimum), worst case outcome (maximum) and the most likely outcome (not set for uniform distribution since all are equally likely). Project professionals use their own experience, with some historical data, to set the parameters of these distributions when undertaking QSRA. After all the uncertainties are set, you can simply use monte-carlo sampling to get an overall distribution for your project end date and for any key milestones in between.
One great thing that QSRA introduced into the project delivery world is this idea of thinking about the world in a probabilistic way. Humans are riddled with biases when it comes to thinking about the future, so having a quantitative way of discovering all the ranges of possible outcomes helps us make better and more objective decisions.
However, there are limitations to how QSRA works in the industry today. Firstly, activity duration uncertainties are largely determined by humans and therefore still subject to the same biases mentioned above. Secondly, it is a lot of manual effort to agree on uncertainties for all activities in a project before running the whole analysis, meaning that QSRA tends to be undertaken on higher-level “summary” schedules. Lastly, and the limitation I want to focus on most, is that QSRA completely disregards long-tail events.
Notice how all three distributions illustrated above are bounded, one must explicitly define a minimum and a maximum. Furthermore, it is uncommon to find any maximum bounds used in QSRA that are to the scale of the tails we see in our historical dataset (i.e. to the order of 10x planned duration or more). We are therefore missing an entire range of possible outcomes for our project!
Why is this important? If we go back to the original premise that most project delay is created by activities that are heavily delayed, then how can we afford to ignore modeling these kinds of events in a process that is supposed to provide us with more clarity and better decisions?
In the next post of this series, I will dive deeper into how using different distributions in the QSRA process can lead to vastly different outcomes, and how we can start thinking about modeling extreme events.
.png)
.jpg)



